For this exercise, we were given a code, then we were asked to have certain images to test on the code. There are 4 images, one has high contrast, one has low; one taken in daytime, one taken in night time. The code can convert the images to Image Negative, Dimmed Image, and Brightened Image.
Original Images




Image Negatives. The images look amazing here. Though the converted nighttime image is close to being all-white, it still looks good in negative.




Dimmed Images. The effect of dimming the images made them look like nighttime images.




Brightened Images. The brightened images made them look like some fog was all over the camera causing the effect. It's more noticeable on the daytime photo.




The next task was to get the gray images of the same photos, then get their histograms.


This one has many white and gray levels.

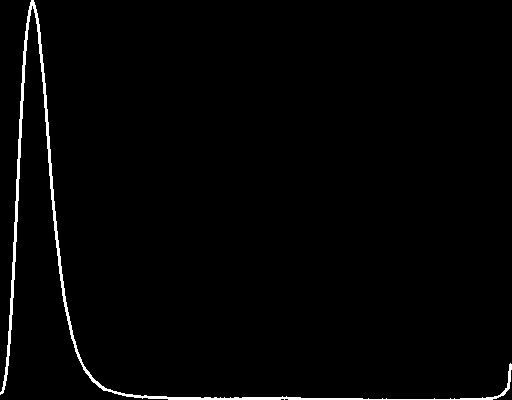
Since the original image was a nighttime image, most of the colors were dark, thus there are more black levels and grayish-black levels.


While the original images was a day time images, due to binarization, there were more gray levels than white levels.


This one had more black levels compared to gray and white levels.

















